Today I have collected a small amplifier IC circuit for you. Most of the old series. and It is a simple circuit OTL series, mini size capacitor coupling to small speakers.
Although the number of IC may not be stock. It’s very hard to find now. But may have come across in Small electric appliances such as TV, radio receivers, tape player, radio, toys, etc.
But sometimes you may have to repair them, or perhaps you might be stored in the power storage.
The idea was to create the best sound amplifier. And use less power supply so secure, that.
I hope this is helpful to you.
Note: at present We can’t find these ICs anymore. I recommend that if you want a Mini audio amplifier chip, choose an LM386 audio amplifier, it’s easy to buy.
6W Power Amplifier circuit using TBA810
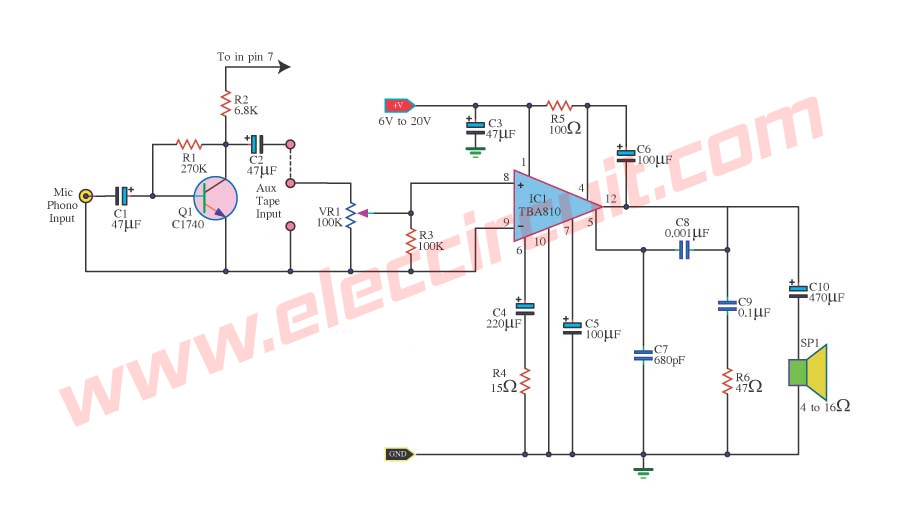
This is the circuit that amplifies small-sized 6W only just. but build easy sound quality can use and durable. Because use IC TBA810 very circuit is model OTL make a loudspeaker turns difficult very much. Circuit detail and PCB see in a picture.
Recommended: 3 transistor audio amplifier circuit
7 watts Power Amplifier Circuit using TBA810
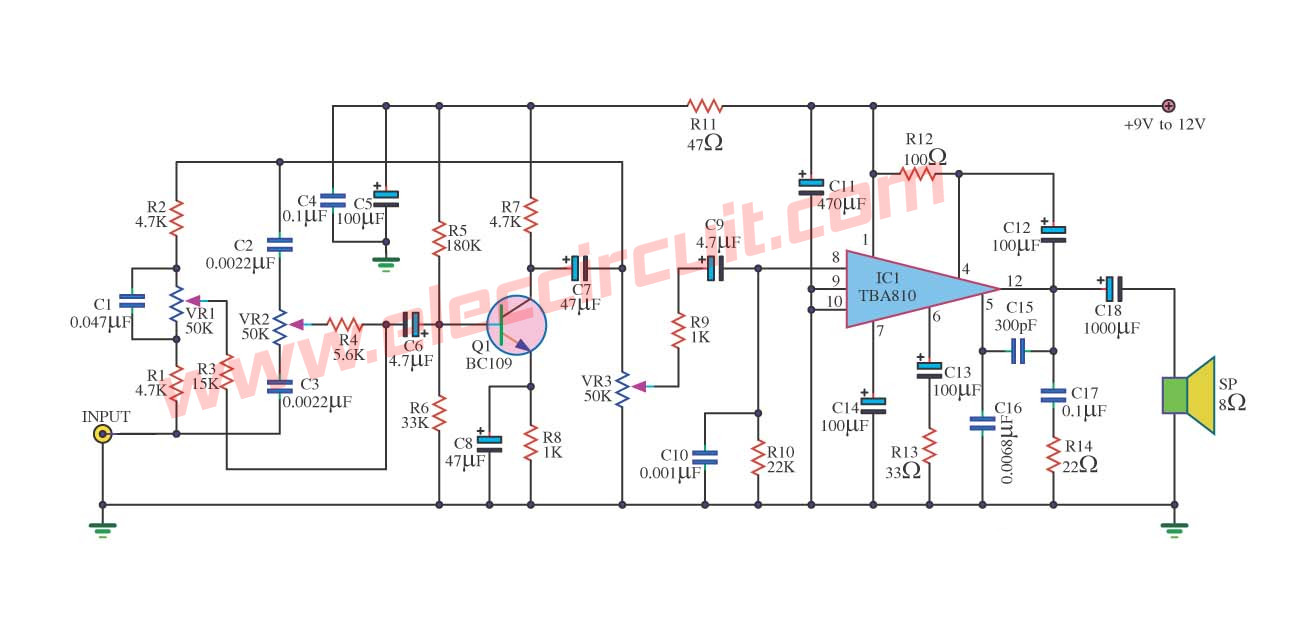
This is a small power Amplifier Circuit. First of all, we build to keep it usable. By using the integrated circuit TBA810. It has 7watt character sizes OTL then build good easy.
And still, a button fines to decorate the sound fully such as Volume, Bass, Treble.
And use Voltage supply 9V-12V only. We will be convenient for the initiator builds power Amplifier Circuit. Let’s get enjoy.
Power Amplifier Monolithic Integrated Circuit using TDA1910
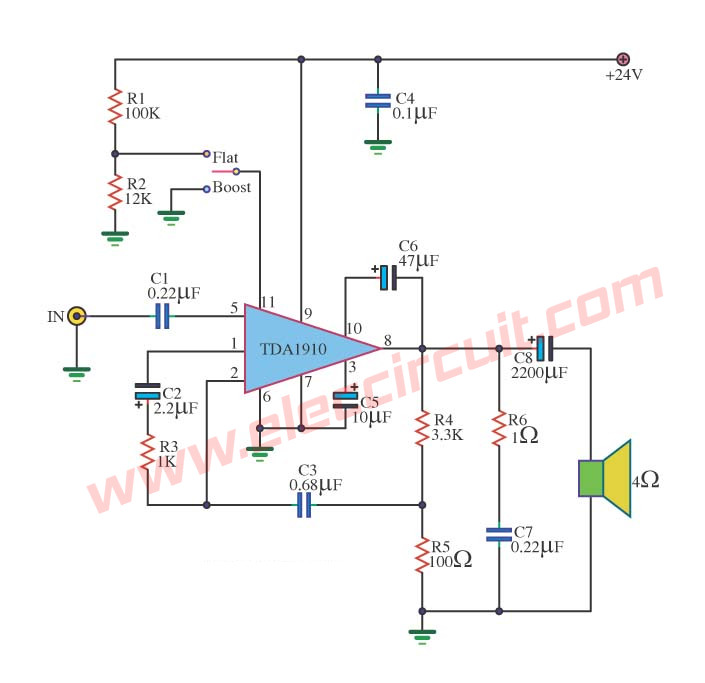
Here is the TDA1910 monolithic integrated circuit.
* 10 dB 50Hz boost tone control using change of pin 1 resistance (muting function)
We try to come to see Power Amplifier Monolithic Integrated Circuit IC TDA1910. It very the circuit is the character Amplifier OTL.
Then build an easy and use voltage supply of about 24V will make have the electric power comes out about 15W-18Watt at 4-ohm loudspeakers unless. It has S1 for choosing the pitch Flat or Boost get as well. Then the circuit amplifies at good interesting request enjoy yes.
TDA2006 Audio Power Amplifier Circuit,OTL 12W with Single power supply
The Circuit TDA2006 Amplifier audio OTL 12W with a single power supply.
The voltage supply 11V to 14V, Power output 12W, for Speaker 2-8 ohm.
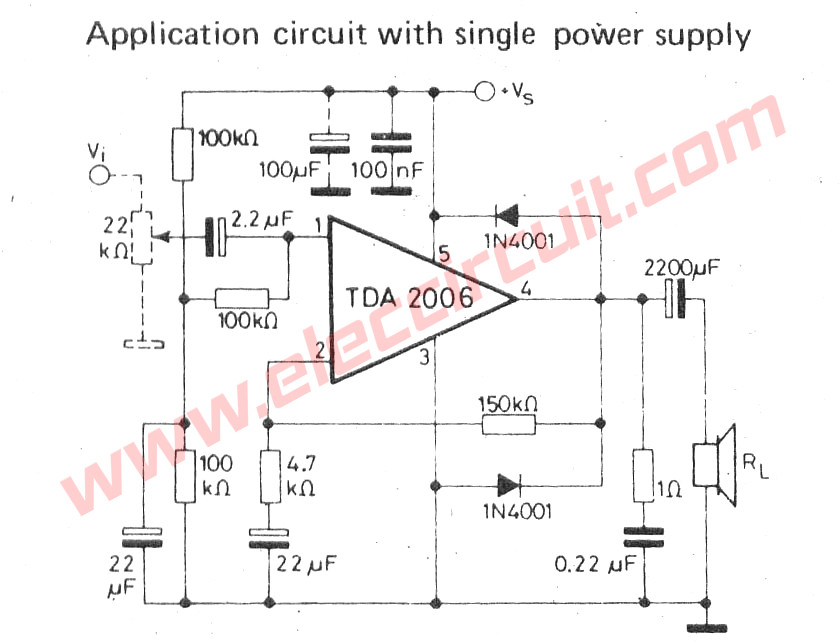
Schematic Diagram of TDA2006/ OTL 12 watts Power Amplifier with single power supply
TDA1904 Audio Amplifier OTL 4W
This circuit I take the IC TDA1904 form the amplifier section in a old color television. The tube can not be fixed. But the circuit have low watt so for the beginner or simple project only.
It has a few detail because use IC and a little part three resistors and three capacitors. I have to try with speaker 4 ohm so output 4 watt, and power supply 9V to 20V,for small size room. When build complete I and my family are enjoyed.
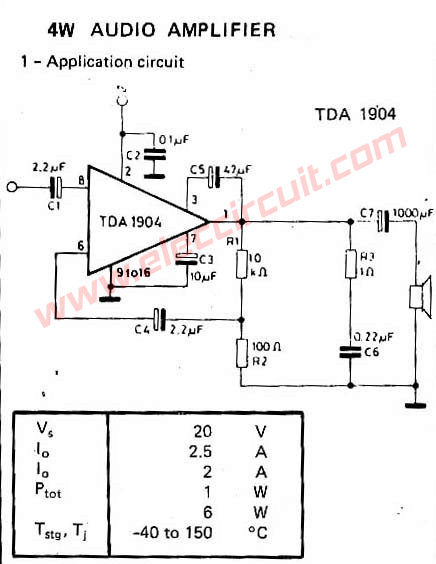
The Schematic Diagram of TDA1904 Audio Amplifier OTL 4W
LM379 Power Amplifier OTL Stereo 6W+6W
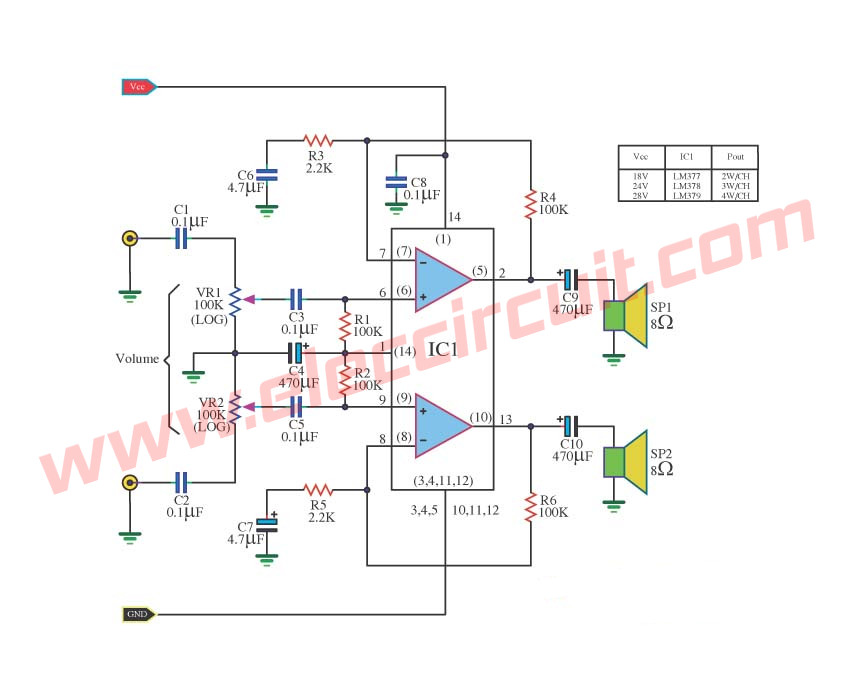
Here is circuit power Amplifier OTL Stereo 6W+6W, Use IC LM379,LM377,LM378.
Voltage supply for this circuit,See in picture.
LM390/ OTL 1W/ Power Amplifier Circuit
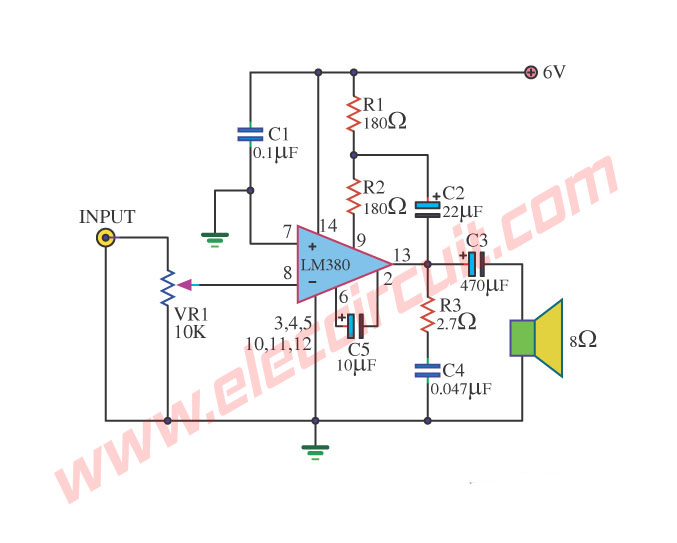
This is a mini power amplifier OTL 1watt. By using the integrated circuit LM390. Be pillar equipment perform enlarge sound signal gives the power goes up. For apply to 4ohm loudspeakers convenient for electronics small-sized circuit. That use Voltage Supply just 6Volt request a friend has fun Small Amplifier, please sir.
Power Amplifier Sqelch function in TV using TDA1910
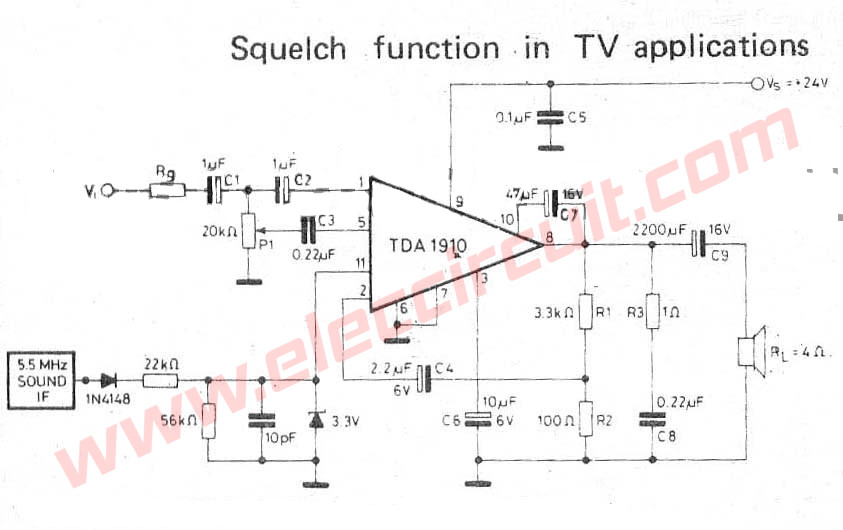
The circuit TDA1910 Sqelch function in TV, INPUT Sound IF 5.5MHZ.
I meet this circuit from one white black old television. It is the circuit in a part that amplifies systematically decrease disturbance sound signal. Fine decorate the sound with Voltage DC control.
I think this our circuit has can to apply outside work with and the little equipment. Then economize good, may advantage with friends.
Mini amplifier for computer music
This is a mini old amplifier circuit that used an Op-Amp Audio Amplifier to have strip zone frequency wide. It develops upward for apply to change the digital signal to the analog signal circuit (DAC) and change low filter circuit. For be born the sound of music.
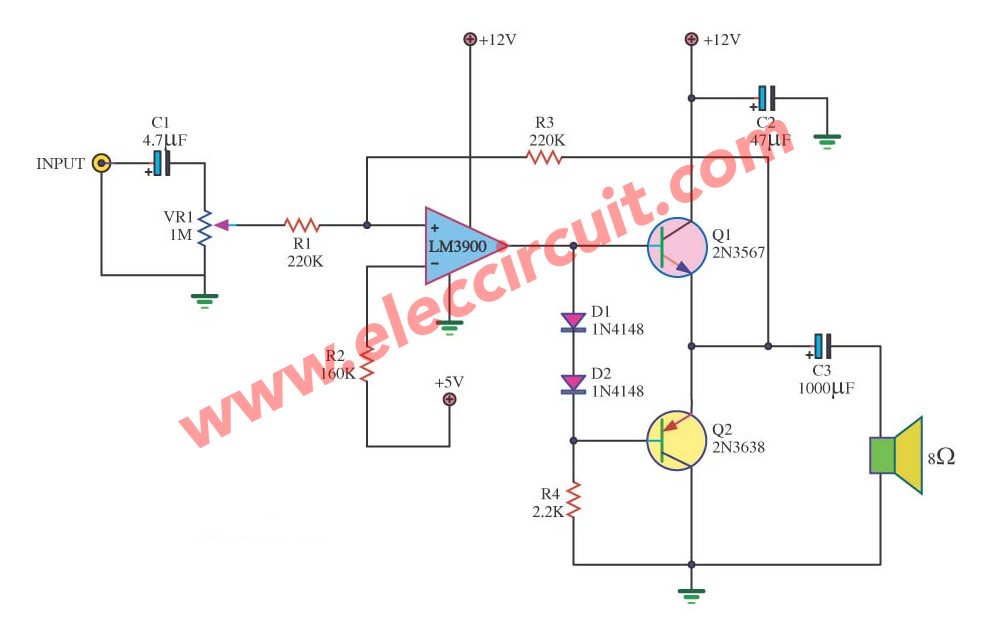
Which build by a Chinese gambling cow staggers to stagger, By the circuit composes op-amp IC LM3900 perform amplify at the beginning, as a result, driver the sound with dual transistor subsequently submit go to still a loudspeaker next. see other detail in the circuit.
GET UPDATE VIA EMAIL
I always try to make Electronics Learning Easy.
I love electronic circuit. I will collect a lot circuit electronic for teach my son and are useful for everyone.

This site truly has all of the info I needed about this subject and didn’t
know who to ask.
i want on paper design example of power amplifier using ic TBA 810 not circuit digram
I learned so much reading this. Like how to fine decorate the sound, and boost get.
I am certain that everyone in EE will benefit greatly from reading this information, especially on how to economise good. Thank-you sir.
i do not know how much the e books cost? who and is the payment connection secure, what type of fileis the e book?
Hello Ryan Green,
I am very happy that you are interested in supporting my e-book.
Please go to: https://www.buymeacoffee.com/eleccircuits/extras
It is pdf files, You can pay by credit card with satisfaction guaranteed and a refund in any case.
Thank you in advance.